Back To Caching
I Skipped Bucket Day
I’m back, and I’m about to get even deeper into zink’s descriptor management. I figured everyone including me is well acquainted with bucket allocating, so I skipped that day and we can all just imagine what that post would’ve been like instead.
Let’s talk about caching and descriptor sets.
I talked about it before, I know, so here’s a brief reminder of where I left off:
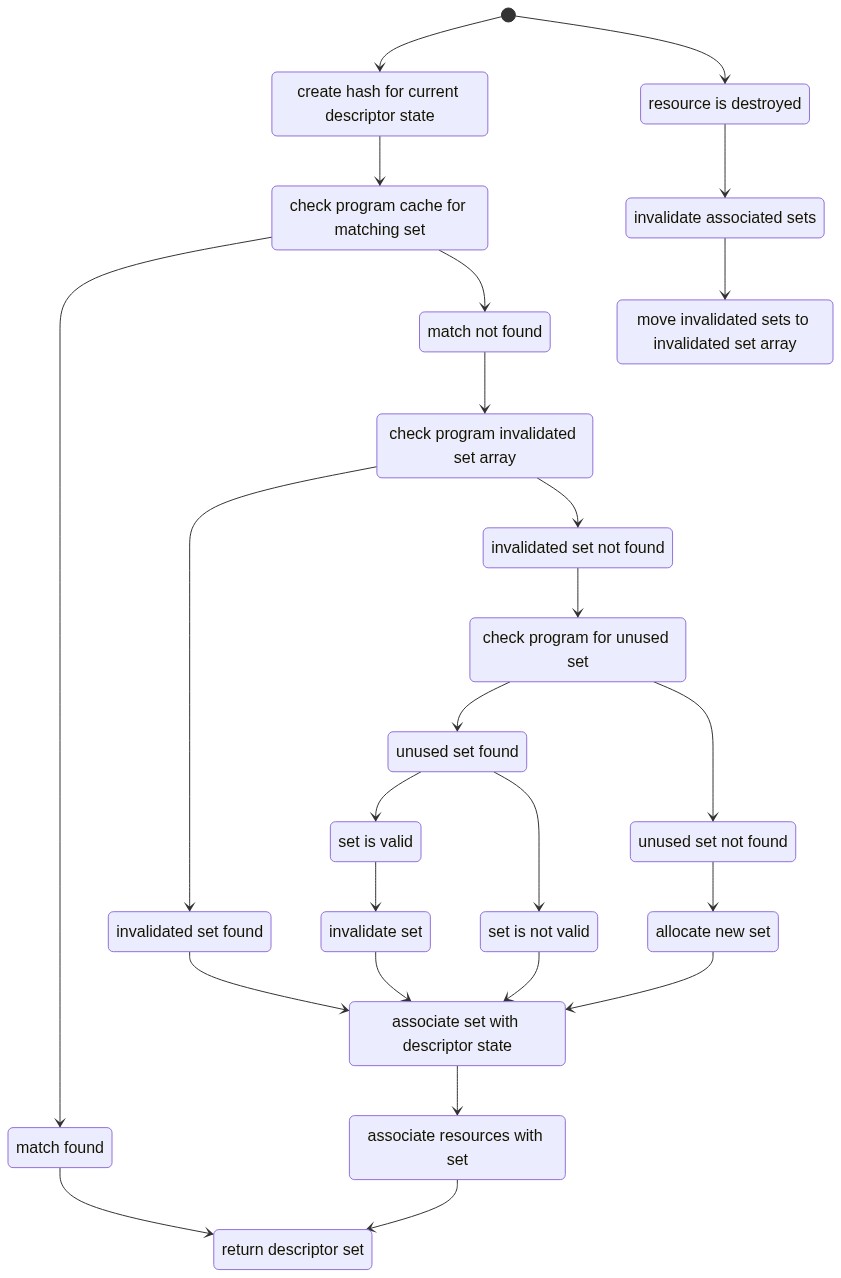
Just a very normal cache mechanism. The problem, as I said previously, was that there was just way too much hashing going on, and so the performance ended up being worse than a dumb bucket allocator.
Not ideal.
But I kept turning the idea over in the back of my mind, and then I realized that part of the problem was in the upper-right block named move invalidated sets to invalidated set array. It ended up being the case that my resource tracking for descriptor sets was far too invasive; I had separate hash tables on every resource to track every set that a resource was attached to at all times, and I was basically spending all my time modifying those hash tables, not even the actual descriptor set caching.
So then I thought: well, what if I just don’t track it that closely?
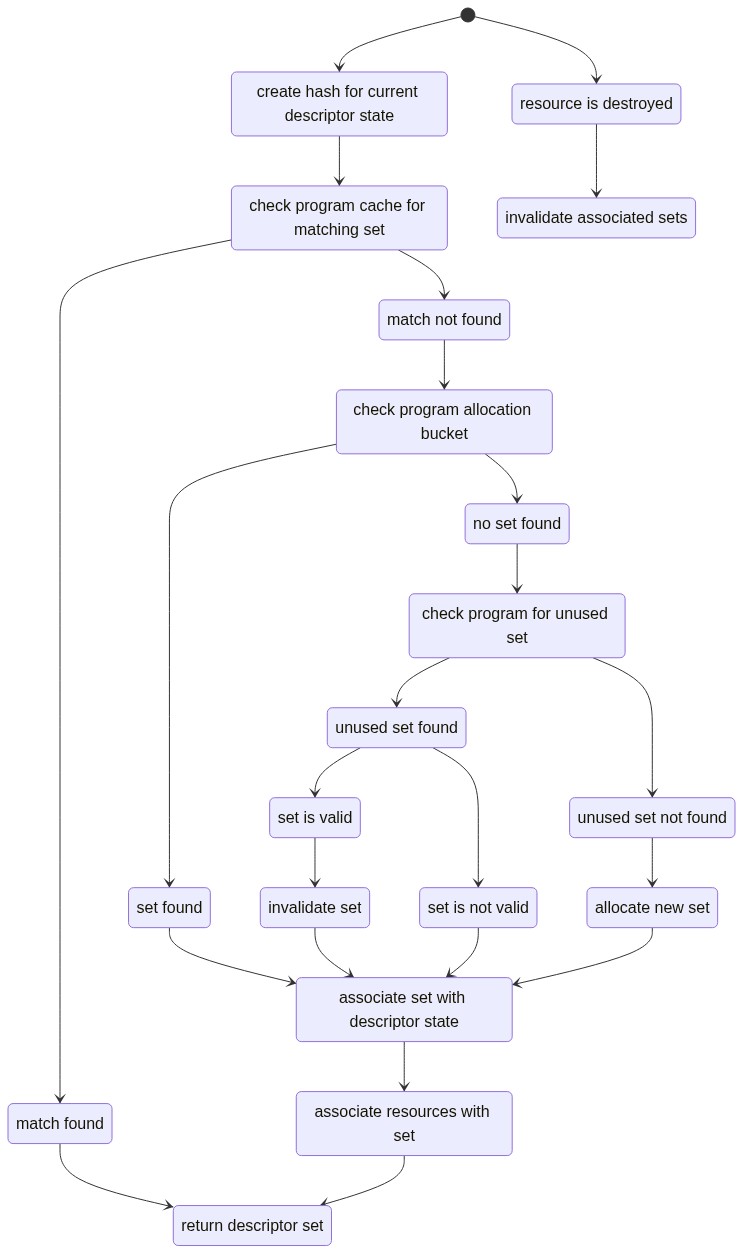
Indeed, this simplifies things a bit at the conceptual level, since now I can avoid doing any sort of hashing related to resources, though this does end up making my second-level descriptor set cache less effective. But I’m getting ahead of myself in this post, so it’s time to jump into some code.
Resource Tracking 2.0
Instead of doing really precise tracking, it’s important to recall a few key points about how the descriptor sets are managed:
- they’re bucket allocated
- they’re allocated using the
struct zink_programralloc context - they’re only ever destroyed when the program is
- zink is single-threaded
Thus, I brought some pointer hacks to bear:
void
zink_resource_desc_set_add(struct zink_resource *res, struct zink_descriptor_set *zds, unsigned idx)
{
zds->resources[idx] = res;
util_dynarray_append(&res->desc_set_refs, struct zink_resource**, &zds->resources[idx]);
}
This function associates a resource with a given descriptor set at the specified index (based on pipeline state). And then it pushes a reference to that pointer from the descriptor set’s C-array of resources into an array on the resource.
Later, during resource destruction, I can then walk the array of pointers like this:
util_dynarray_foreach(&res->desc_set_refs, struct zink_resource **, ref) {
if (**ref == res)
**ref = NULL;
}
If the reference I pushed earlier is still pointing to this resource, I can unset the pointer, and this will get picked up during future descriptor updates to flag the set as not-cached, requiring that it be updated. Since a resource won’t ever be destroyed while a set is in use, this is also safe for the associated descriptor set’s lifetime.
And since there’s no hashing or tree traversals involved, this is incredibly fast.
Second-level Caching
At this point, I’d created two categories for descriptor sets: active sets, which were the ones in use in a command buffer, and inactive sets, which were the ones that weren’t currently in use, with sets being pushed into the inactive category once they were no longer used by any command buffers. This ended up being a bit of a waste, however, as I had lots of inactive sets that were still valid but unreachable since I was using an array for storing these as well as the newly-bucket-allocated sets.
Thus, a second-level cache, AKA the B cache, which would store not-used sets that had at one point been valid. I’m still not doing any sort of checking of sets which may have been invalidated by resource destruction, so the B cache isn’t quite as useful as it could be. Also:
- the
check program cache for matching sethas now been expanded to two lookups in case a matching set isn’t active but is still configured and valid in the B cache - the
check program for unused setblock in the above diagram will now cannibalize a valid inactive set from the B cache rather than allocate a new set
The last of these items is a bit annoying, but ultimately the B cache can end up having hundreds of members at various points, and iterating through it to try and find a set that’s been invalidated ends up being impractical just based on the random distribution of sets across the table. Also, I only set the resource-based invalidation up to null the resource pointer, so finding an invalid set would mean walking through the resource array of each set in the cache. Thus, a quick iteration through a few items to see if the set-finder gets lucky, otherwise it’s clobbering time.
And this brought me up to about 24fps, which was still down a bit from the mind-blowing 27-28fps I was getting with just the bucket allocator, but it turns out that caching starts to open up other avenues for sizable optimizations.
Which I’ll get to in future posts.