Last Day
This Is The End
…of my full-time hobby work on zink.
At least for a while.
More on that at the end of the post.
Before I get to that, let’s start with yesterday’s riddle. Anyone who chose this pic
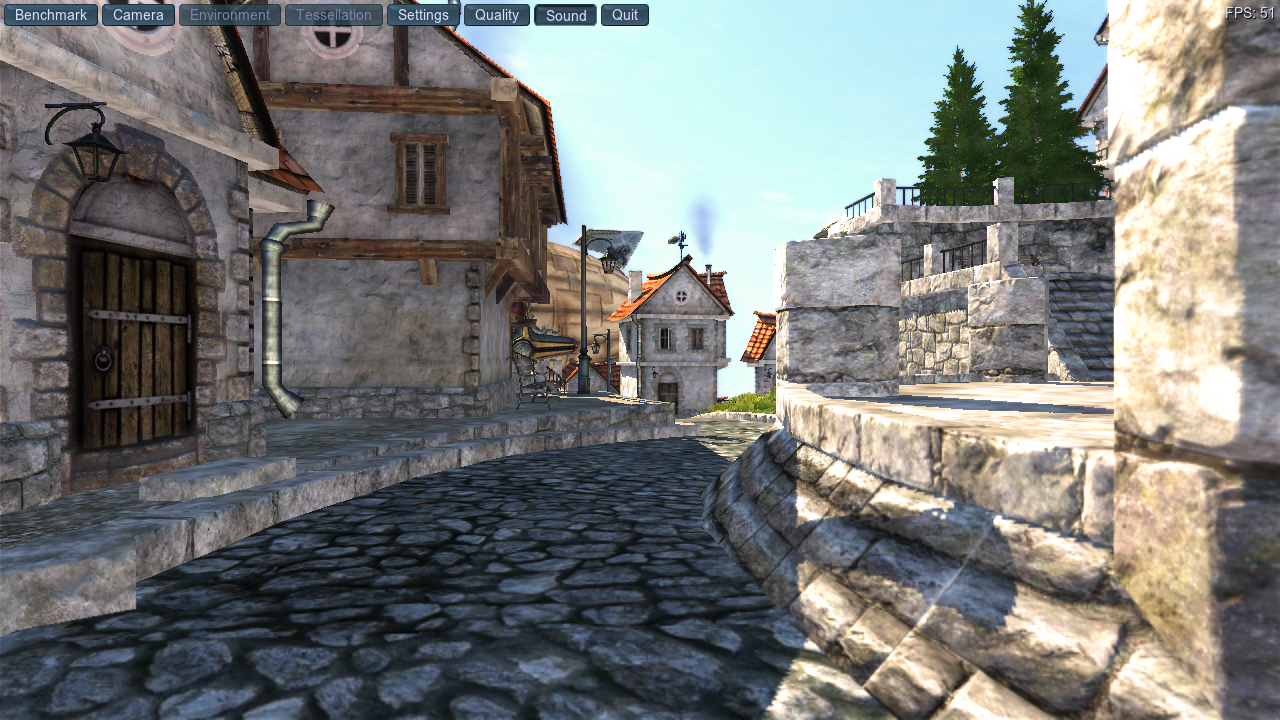
with 51 fps as being zink, you were correct.
That’s right, zink is now at around 95% of native GL performance for this benchmark, at least on my system.
I know there’s been a lot of speculation about the capability of the driver to reach native or even remotely-close-to-native speeds, and I’m going to say definitively that it’s possible, and performance is only going to increase further from here.
A bit of a different look on things can also be found on my Fall roundup post here.
A Big Boost From Threads
I’ve long been working on zink using a single-thread architecture, and my goal has been to make it as fast as possible within that constraint. Part of my reasoning is that it’s been easier to work within the existing zink architecture than to rewrite it, but the main issue is just that threads are hard, and if you don’t have a very stable foundation to build off of when adding threading to something, it’s going to get exponentially more difficult to gain that stability afterwards.
Reaching a 97% pass rate on my piglit tests at GL 4.6 and ES 3.2 gave me a strong indicator that the driver was in good enough shape to start looking at threads more seriously. Sure, piglit tests aren’t CTS; they fail to cover a lot of areas, and they’re certainly less exhaustive about the areas that they do cover. With that said, CTS isn’t a great tool for zink at the moment due to the lack of provoking vertex compatibility support in the driver (I’m still waiting on a Vulkan extension for this, though it’s looking likely that Erik will be providing a fallback codepath for this using a geometry shader in the somewhat near future) which will fail lots of tests. Given the sheer number of CTS tests, going through the failures and determining which ones are failing due to provoking vertex issues and which are failing due to other issues isn’t a great use of my time, so I’m continuing to wait on that. The remaining piglit test failures are mostly due either to provoking vertex issues or some corner case missing features such as multisampled ZS readback which are being worked on by other people.
With all that rambling out of the way, let’s talk about threads and how I’m now using them in zink-wip.
At present, I’m using u_threaded_context, making zink the only non-radeon driver to implement it. The way this works is by using Gallium to write the command stream to a buffer that is then processed asynchronously, freeing up the main thread for application use and avoiding any sort of blocking from driver overhead. For systems where zink is CPU-bound in the driver thread, this massively increases performance, as seen from the ~40% fps improvement that I gained after the implementation.
This transition presented a number of issues, the first of which was that u_threaded_context required buffer invalidation and rebinding. I’d had this on my list of targets for a while, so it was a good opportunity to finally hook it up.
Next up, u_threaded_context was very obviously written to work for the existing radeon driver architecture, and this was entirely incompatible with zink, specifically in how the batch/command buffer implementation is hardcoded like I talked about yesterday. Switching to monotonic, dynamically scaling command buffer usage resolved that and brought with it some other benefits.
The other big issue was, as I’m sure everyone expected, documentation.
I certainly can’t deny that there’s lots of documentation for u_threaded_context. It exists, it’s plentiful, and it’s quite detailed in some cases.
It’s also written by people who know exactly how it works with the expectation that it’s being read by other people who know exactly how it works. I had no idea going into the implementation how any of it worked other than a general knowledge of the asynchronous command stream parts that are common to all thread queue implementations, so this was a pretty huge stumbling block.
Nevertheless, I persevered, and with the help of a lot of RTFC, I managed to get it up and running. This is a more general overview post rather than a more in-depth, technical one, so I’m not going to go into any deep analysis of the (huge amounts of) code required to make it work, but here’s some key points from the process in case anyone reading this hits some of the same issues/annoyances that I did:
- use consistent naming for all your struct subclassing, because a huge amount of the code churn is just going to be replacing
driver class -> gallium classreferences todriver class -> u_threaded_context class -> gallium classones; if you cansedthese all at once, it simplifies the work tremendously u_threaded_contextworks off the radeon queue/fence architecture, which allows (in some cases) multiple fences for any given queue submission, so ensure that your fences work the same way or (as I did) can effectively have sub-fences- obviously don’t forget your locking, but also don’t over-lock; I’m still doing some analysis to check how much locking I need for the context-based caches, and it may even be the case that I’m under-locked at the moment, but it’s important to keep in mind that your
pipe_contextcan be in many different threads at a given time, and so, as theu_threaded_contextdocs repeatedly say without further explanation, don’t use it “in an unsafe way” - the buffer mapping rules/docs are complex, but basically it boils down to checking the
TC_TRANSFER_MAP_*flags before doing the things that those flags prohibit- ignore
threaded_resource::max_forced_staging_uploadsto start with since it adds complexity - if you get
TC_TRANSFER_MAP_THREADED_UNSYNC, you have to usethreaded_context::base.stream_uploaderfor staging buffers, though this isn’t (currently) documented anywhere - watch your buffer alignments; I already fixed an issue with this, but
u_threaded_contextwas written for radeon drivers, so there may be other cases where hardcoded values for those drivers exist - probably just read the radeonsi code before even attempting this anyway
- ignore
All told, fixing all the regressions took much longer than the actual implementation, but that’s just par for the course with driver work.
Anyone interested in testing should take note that, as always, this has only been used on Intel hardware (and if you’re on Intel, this post is definitely worth reading), and so on systems which were not CPU-bound previously or haven’t been worked on by me, you may not yet see these kinds of gains.
But you will eventually.
And That’s It
This is a sort of bittersweet post as it marks the end of my full-time hobby work with zink. I’ve had a blast over the past ~6 months, but all things change eventually, and such is the case with this situation.
Those of you who have been following me for a long time will recall that I started hacking on zink while I was between jobs in order to improve my skills and knowledge while doing something productive along the way. I succeeded in all regards, at least by my own standards, and I got to work with some brilliant people at the same time.
But now, at last, I will once again become employed, and the course of that employment will take me far away from this project. I don’t expect that I’ll have a considerable amount of mental energy to dedicate to hobbyist Open Source projects, at least for the near term, so this is a farewell of sorts in that sense. This means (again, for at least the near term):
- I’ll likely be blogging far less frequently
- I don’t expect to be writing any new patches for zink/gallium/mesa
This does not mean that zink is dead, or the project is stalling development, or anything like that, so don’t start overreaching on the meaning of this post.
I still have 450+ patches left to be merged into mainline Mesa, and I do plan to continue driving things towards that end, though I expect it’ll take a good while. I’ll also be around to do patch reviews for the driver and continue to be involved in the community.
I look forward to a time when I’ll get to write more posts here and move the zink user experience closer to where I think it can be.
This is Mike, signing off for now.
Happy rendering.