All The Updates
EBUSY
As everyone knows, SGC goes into yearly hibernation beginning in November. Leading up to that point has been a mad scramble to nail down all the things, leaving less time for posts here.
But there have been updates, and I’m gonna round ‘em all up.
R A Y T R A C W T F
Friend of the blog and future Graphics scientist with a PhD in WTF, Konstantin Seurer, has been hard at work over the past several weeks. Remember earlier this year when he implemented VK_EXT_descriptor_indexing for Lavapipe? Well he’s at it again, and this time he’s aimed for something bigger.
He’s now implemented raytracing for Lavapipe.
It’s a tremendous feat, one that sets him apart from the other developers who have not implemented raytracing for a software implementation of Vulkan.
CLosure
I blogged (or maybe imagined blogging) about RustiCL progress on zink last year at XDC, specifically the time renowned pubmaster Karol Herbst handcuffed himself to me and refused to divulge the location of the key (disguised as a USB thumb drive in his laptop) until we had basic CL support functioning in a pair programming exercise that put us up against the unnaturally early closing time of Minneapolis pubs. That episode is finally turning into something useful as CL support for zink will soon be merged.
While I can’t reveal too much about the performance as of yet, what I can say now is that it’s roughly 866% faster.
Fixups
A number of longstanding bugs have recently been fixed.
Wolfenstein Face
Anyone who has tried to play one of the modern Wolfenstein GL games on RADV has probably seen this abomination:
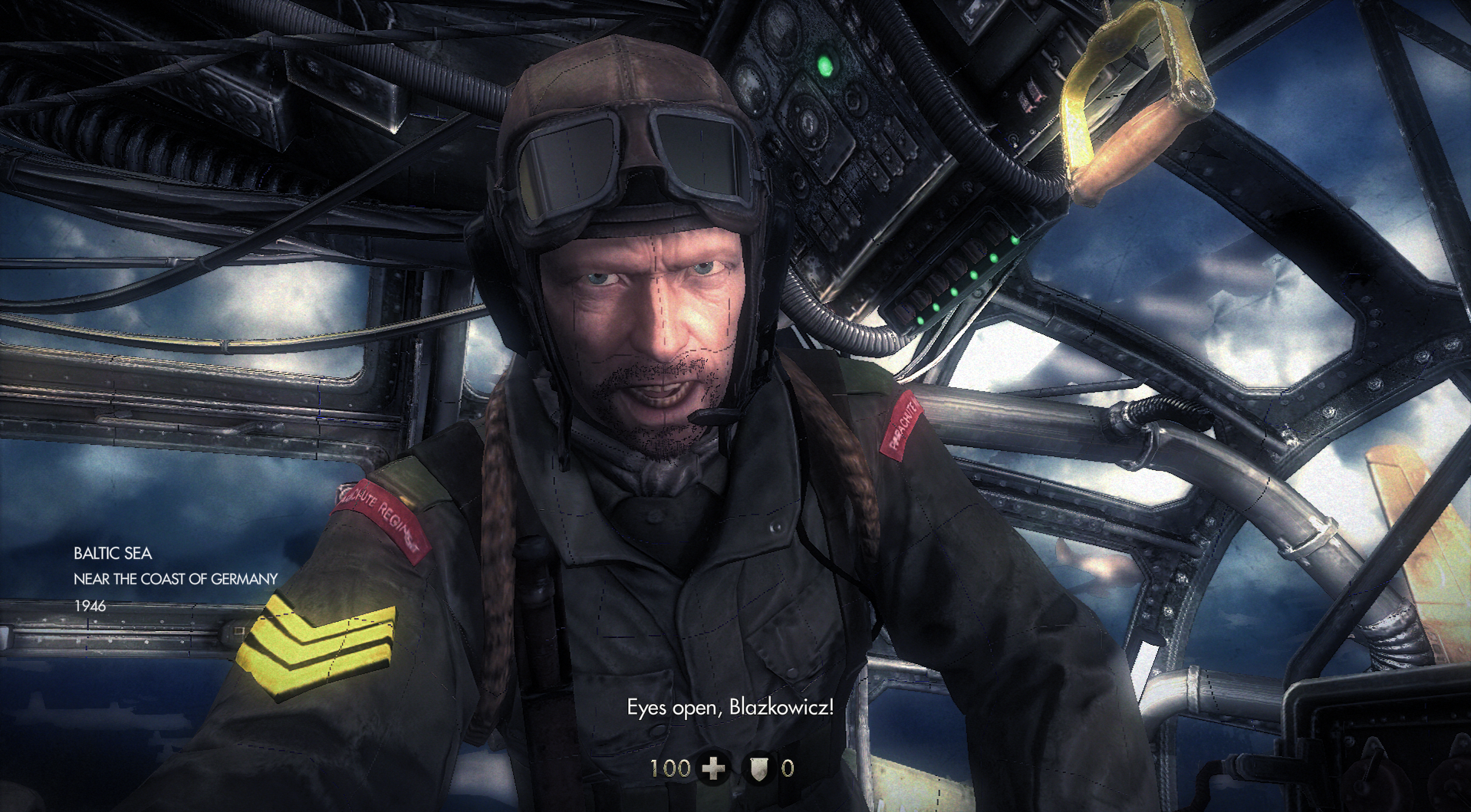
Wolfenstein Face affects a very small number of apps. Actually just the Wolfenstein (The New Order / The Old Blood) games. I’d had a ticket open about it for a while, and it turns out that this is a known issue in D3D games which has its own workaround. The workaround is now going to be applied for zink as well, which should resolve the issue while hopefully not causing others.
Apitrace: The Final Frontier
Since the dawn of time, experts have tried to obtain traces from games with rendering bugs, but some of these games have historically been resistant to tracing.
- A number of games could be traced, but then replaying those traces would crash at a certain point. This is now fixed, enabling better bug reporting for a large number of AAA games from the the last decade.
- Another set of games using the id Engine could record traces, but then replaying them would fail to render correctly:

This affects (at least) Wolfenstein: The Old Blood and DOOM2016, but the problem has been identified, and a fix is on the way.
Zink: Exploring New Display Systems
After a number of universally-reviled hacks, Zink should now work fine in both Wayland and Surfaceless EGL configurations.
The Real Post
Any other, lesser blogger would’ve saved this for another post in order to maximize their posting frequency metric, but here at SGC the readers get a full meal with every post even when they don’t have enough time to digest it all at once. Since I’m not going to XDC this year, consider this the thing I might have given a presentation on.
During my executive senior keynote seminar presentation workshop on zink at last year’s XDC, I brought up tiler performance as one of the known deficiencies. Specifically this was in regard to how tilers need to maximize time spent inside renderpasses and avoid unnecessary load/store operations when beginning/ending those renderpasses, which required either some sort of Vulkan extension to enable deferred load/store op setting OR command stream parsing for GL.
While I did work on a number of Vulkan extensions this year, deferred load/store ops wasn’t one of them.
So it was that I implemented renderpass tracking for Threaded Context to scan the GL command stream in the course of recording it for threaded dispatch. The CPU overhead is negligible (~5% on a couple extremely synthetic drawoverhead cases and nothing noticeable in apps), while the performance gains are staggering (~10-15x speedup in AAA games). All in all, it was a painful process but one that has yielded great results.
The gist of it, as I’ve described in previous posts that I’m too lazy to find links for, is that framebuffer attachment access is accumulated during TC command recording such that zink is able to determine which load/store ops are needed. This works great so long as nothing unexpected splits the renderpass. “Unexpected” in this context refers to one of the following scenarios:
- zink receives a (transfer) command sequence which is impossible to reorder and must split the renderpass to execute copies/blits
- the app randomly flushes during rendering
- the GL frontend hits a TC synchronization point and halts the recording thread to wait for the driver thread to finish execution
The final issue remaining for renderpass tracking has been this third scenario: any time the GL frontend needs to sync TC, renderpass metadata is split. The splitting is such that a single renderpass becomes two because the driver must complete execution on the currently-recorded metadata in order to avoid deadlocking itself against the waiting GL frontend, but then the renderpass will continue after the sync. While this happens in a very small number of scenarios, one of them is quite common.
Texture uploading.
Texture Uploads: How Do They Work?
There are (currently) three methods by which TC can perform texture uploads:
- for small uploads, the data is enqueued and passed asynchronously to the driver thread
- for larger uploads:
- if renderpass tracking is enabled and a renderpass is active, the upload will be sequenced into N strided uploads and passed asynchronously to the driver thread to avoid splitting renderpasses
- otherwise TC syncs the driver thread and performs the upload directly
Eagle-eyed readers will notice that I’ve already handled the “problem” case described above; in order to avoid splitting renderpasses, I’ve written some handling which rewrites texture uploads into a sequence of N asynchronous buffer2image copies, where N is either 1 or $height depending on whether the source data’s stride matches the image’s stride. In the case where N is not 1, this can result in e.g., 4096 copy operations being enqueued for a 4096x4096 texture atlas. Even in the case where N is 1, it still adds an extra full copy of the texture data. While this is still more optimal than splitting a renderpass, it’s not optimal in the absolute sense.
You can see where this is going.
TC Execution: Define Optimal
Optimal Threaded Context execution is the state when the GL frontend is recording commands while the driver thread is deserializing those commands into hardware-specific instructions to submit to the GPU. Visually, it looks like this Halloween-themed diagram:

Ignoring the small-upload case, the current state of texture uploading looks like one of the following Halloween-themed diagrams:
- the sequenced upload case will have more work, so the driver thread will run a bit longer than it otherwise would, resulting in the GL frontend waiting a bit longer than it otherwise would for completion

- the sync upload case creates a bubble in TC execution

Solve For P
To maintain maximum performance, TC needs to be processing commands asynchronously in the driver thread while the GL frontend continues to record commands for processing. Thus, to maintain maximum performance during texture uploads, the texture upload needs to occur (without copies) while the driver thread continues executing.
Looking at this problem from a different perspective, the case that needs to be avoided at all costs is the case where the GL frontend syncs TC execution. The reason why this sync exists is to avoid accidentally uploading data to an in-use image, which would cause unpredictable (but definitely wrong) output. In this context, in-use can be defined as an image which is either:
- enqueued in a TC batch for execution
- enqueued/active in a GPU submission
On the plus side, pipe_context::is_resource_busy exists to query the second of these, so that’s solved. On the minus side, while TC has some usage tracking for buffers, it has nothing for images, and adding such tracking in a performant manner is challenging.
To figure out a solution for TC image tracking, let’s examine the most common problem case. In games, the most common scenario for texture uploading is something like this:
- create staging image
- upload texture data to staging image
- draw to scene while sampling staging image
- delete staging image
For such a case, it’d be trivial to add a seen flag to struct threaded_resource and pass the conditional if the flag is false. Since it’s straightforward enough to evaluate when an image has been seen in TC, this would suffice. Unfortunately, such a naive (don’t @ me about diacritics) implementation ignores another common pattern:
- create staging image
- upload texture data to staging image
- draw to scene while sampling staging image
- cache staging image for reuse
- render frame
- upload texture data to staging image
- draw to scene while sampling staging image
- cache staging image for reuse
- render frame
- …
For this scenario, the staging image is reused, requiring a bit more tracking in order to accurately determine that it can be safely used for uploads.
The solution I’ve settled on is to use a derivative of zink’s resource tracking. This adds an ID for the last-used batch to the resource, which can then be checked during uploads. When the image is determined idle, the texture data is passed directly to the driver for an unsynchronized upload similar to how unsynchronized buffer uploads work. It’s simple and hasn’t shown any definitive performance overhead in my testing.
For it to really work to its fullest potential in zink, unfortunately, requires VK_EXT_host_image_copy to avoid further staging copies, and nobody implements this yet in mesa main (except Lavapipe, though also there’s this ANV MR). But someday more drivers will support this, and then it’ll be great.
As far as non-tiler performance gains from this work, it’s hard to say definitively whether they’ll be noticeable. Texture uploads during loading screens are typically intermixed with shader compilation, so there’s little TC execution to unblock, but any game which uses texture streaming may see some slight latency improvements.
The only remaining future work here is to further enable unsynchronized texture uploads in zink by adding a special cmdbuf for unsynchronized uploads to handle the non-HIC case. Otherwise performance should be pretty solid across the board.