Conditional Speed
Intro
I didn’t go into much detail in my last post about all the huuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuge optimizations I’ve been working on (they’re big) with code that totally exists and isn’t made up. The reason was that I didn’t feel like it.
But today’s a different day, and I haven’t done any real blogging in a while. Does that mean…
Big Hashtable Energy
One of the big perf sinks in ET profiling was fragment shader epilog handling.
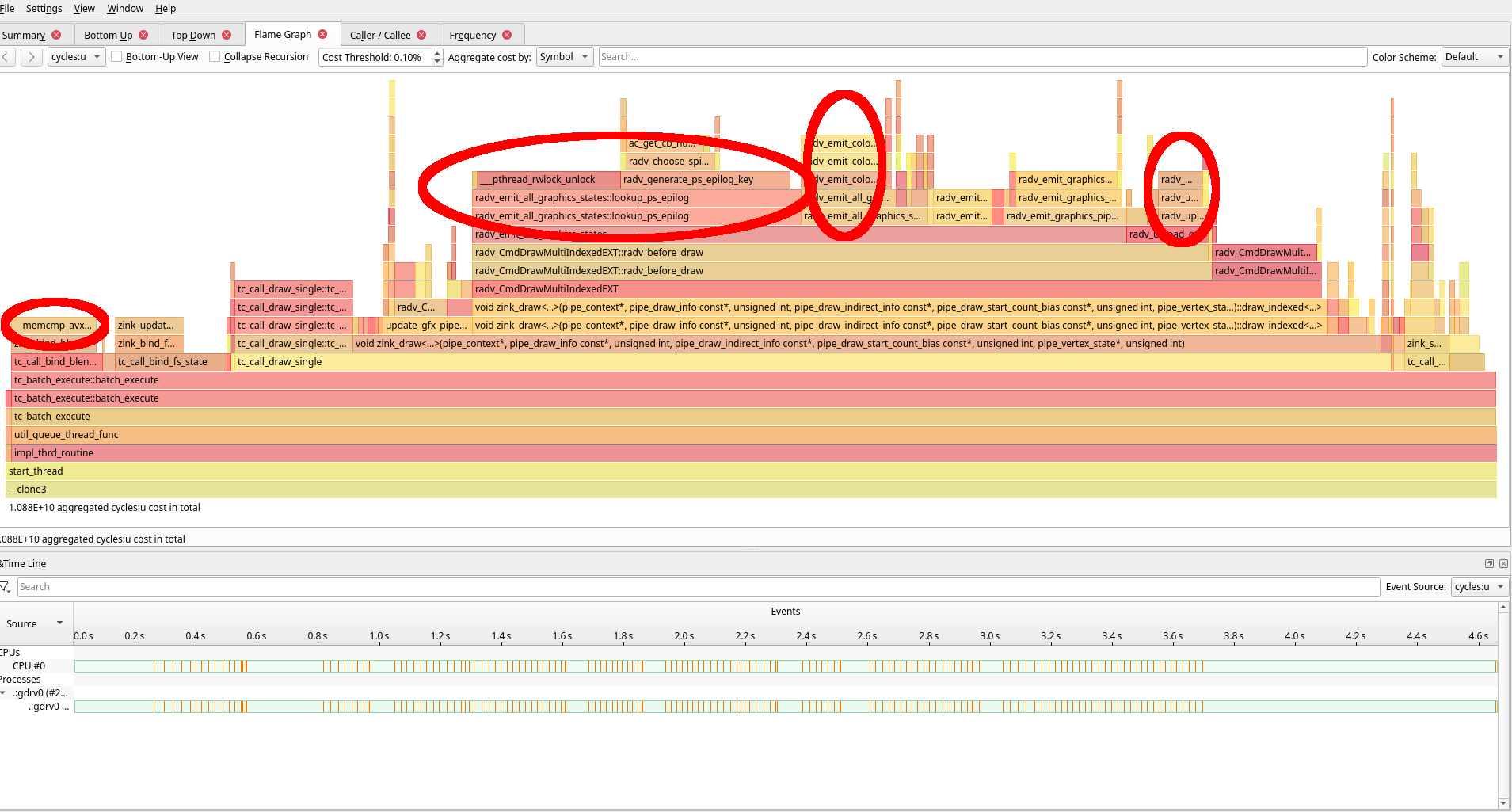
Yeah, that’s the stuff right there in the middle. The lookup is slow, the key generation is slow, and I hate all of it and we already know I’ve taken out the hammer, so let’s skip past more of the profiling details onto some code.
How Do Epilogs (+prologs) Work?
RADV has the same mechanism for prologs and epilogs:
- generate the lookup key
- lock the hash table
- lookup the prolog/epilog
- unlock the hash table
- return the prolog/epilog if it was found
- otherwise:
- lock the hash table again
- generate the prolog/epilog
- insert it to the hash table
- unlock the hash table
- return
In code, it looks like this:
struct radv_ps_epilog_key key = radv_generate_ps_epilog_key(device, &state, true);
uint32_t hash = radv_hash_ps_epilog(&key);
u_rwlock_rdlock(&device->ps_epilogs_lock);
struct hash_entry *epilog_entry =
_mesa_hash_table_search_pre_hashed(device->ps_epilogs, hash, &key);
u_rwlock_rdunlock(&device->ps_epilogs_lock);
if (!epilog_entry) {
u_rwlock_wrlock(&device->ps_epilogs_lock);
epilog_entry = _mesa_hash_table_search_pre_hashed(device->ps_epilogs, hash, &key);
if (epilog_entry) {
u_rwlock_wrunlock(&device->ps_epilogs_lock);
return epilog_entry->data;
}
epilog = radv_create_ps_epilog(device, &key, NULL);
struct radv_ps_epilog_key *key2 = malloc(sizeof(*key2));
if (!epilog || !key2) {
radv_shader_part_unref(device, epilog);
free(key2);
u_rwlock_wrunlock(&device->ps_epilogs_lock);
return NULL;
}
memcpy(key2, &key, sizeof(*key2));
_mesa_hash_table_insert_pre_hashed(device->ps_epilogs, hash, key2, epilog);
u_rwlock_wrunlock(&device->ps_epilogs_lock);
return epilog;
}
return epilog_entry->data;
Since all my readers are performance experts, everyone can see the issues.
Literally everyone.
VROOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOM
Yeah, so this isn’t great. There’s a number of factors here that I’m going to go over for posterity, so I’m expecting that nobody will read the following section because all you experts already know what I’m about to say.
Multiple Hashtable Accesses Bad!
Why do a lookup and then an insertion? Both of these operations perform a lookup, so it’s just two lookups in the worst case scenario. It’s already well-known that Mesa’s hash/set lookups are unusually slow (don’t @ me), so this should be avoided.
The Mesa hash table API doesn’t have a search_or_insert function because of collective laziness, which means it all needs to be converted into a set, which does have the API. And it’s more convenient to work with.
Locking Bad!
Locking is bad. Nobody wants to lock. Why does this have locking? Obviously it needs locking because the data is stored on the device, and the device can be used between threads without restriction, blah, blah, blah, but what if things just didn’t work like that?
Instead of always accessing everything on the device, instead access objects that are thread local. Like command buffers. But nobody wants to be duplicating all the epilog generation since that’s expensive, so this is a case where a two-tiered hash table is optimal:
- epilogs get created onto the device hashtable under lock
- then add them onto the cmdbuf hashtable
Blam, the locking is gone.
Bonus: MRU Reuse
The prolog handling has a mechanism where the last-used prolog is stored to the cmdbuf for immediate reuse if the same data is passed, so copying that over to the epilog handling can improve perf in some corner cases.
How Much Faster Is It?
If I had to give a number, probably at least 1000% faster. Just as a rough estimate.
That Seems Like A Lot
It sure does, but only zink uses any of it, so who cares.
MR is up here, probably to be merged sometime in 2030 depending on the lunar cycle and developer horoscopes permitting reviews.