Funday
Just For Fun
I finally managed to get a complete piglit run over the weekend, and, for my own amusement, I decided to check the timediffs against a reference run from the IRIS driver. Given that the Intel drivers are of extremely high quality (and are direct interfaces to the underlying hardware that I happen to be using), I tend to use ANV and IRIS as my references whenever I’m trying to debug things.
Both runs used the same base checkout from mesa, so all the core/gallium/nir parts were identical.
The results weren’t what I expected.
My expectation when I clicked into the timediffs page was that zink would be massively slower in a huge number of tests, likely to a staggering degree in some cases.
We were, but then also on occasion we weren’t.
As a final disclaimer before I dive into this, I feel like given the current state of people potentially rushing to conclusions I need to say that I’m not claiming zink is faster than a native GL driver, only that for some cases, our performance is oddly better than I expected.
The Good
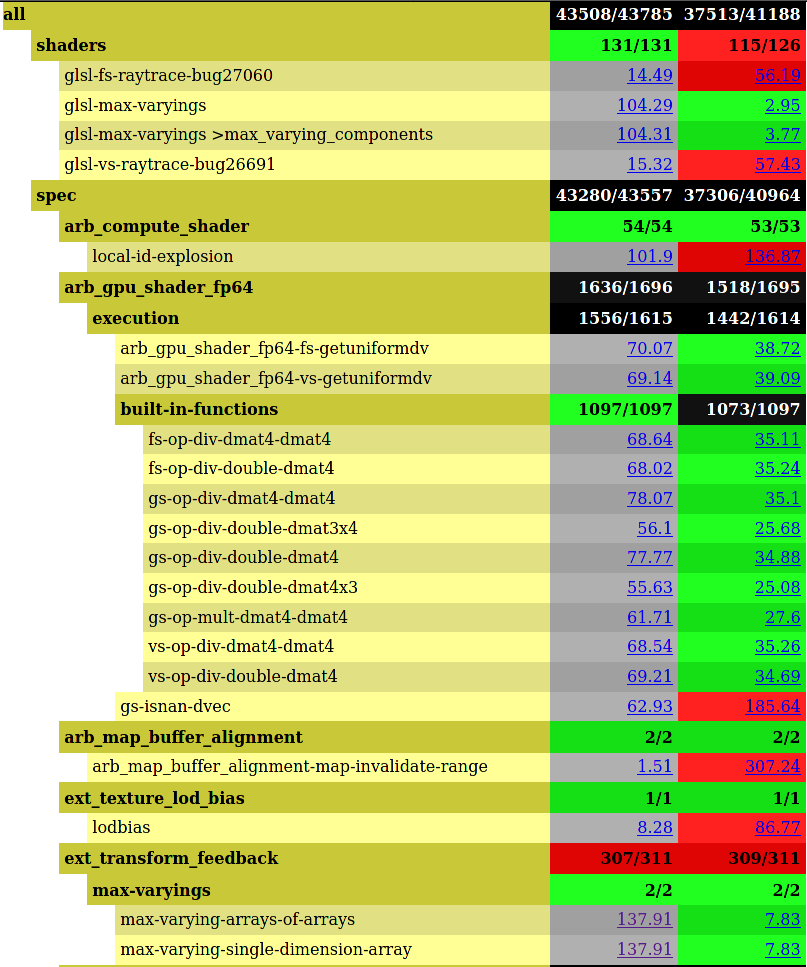
The first thing to take note of here is that IRIS is massively better than zink in successful test completion, with a near-perfect 99.4% pass rate compared to zink’s measly 91%, and that’s across 2500 more tests too. This is important also since timediff only compares between passing tests.
With that said, somehow zink’s codepath is significantly faster when it comes to dealing with high numbers of varying outputs, and also, weirdly, a bunch of dmat4 tests, even though they’re both using the same softfp64 path since my icelake hardware doesn’t support native 64bit operations.
I was skeptical about some of the numbers here, particularly the ext_transform_feedback max-varying-arrays-of-arrays cases, but manual tests were even weirder:
time MESA_GLSL_CACHE_DISABLE=true MESA_LOADER_DRIVER_OVERRIDE=zink bin/ext_transform_feedback-max-varyings -auto -fbo
MESA_GLSL_CACHE_DISABLE=true MESA_LOADER_DRIVER_OVERRIDE=zink -auto -fbo 2.13s user 0.03s system 98% cpu 2.197 total
time MESA_GLSL_CACHE_DISABLE=true MESA_LOADER_DRIVER_OVERRIDE=iris bin/ext_transform_feedback-max-varyings -auto -fbo
MESA_GLSL_CACHE_DISABLE=true MESA_LOADER_DRIVER_OVERRIDE=iris -auto -fbo 301.64s user 0.52s system 99% cpu 5:02.45 total
wat.
I don’t have a good explanation for this since I haven’t dug into it other than to speculate that ANV is just massively better at handling large numbers of varying outputs.
The Bad
By contrast, zink gets thrashed pretty decisively in arb_map_buffer_alignment-map-invalidate-range, and we’re about 150x slower.
Yikes. Looks like that’s going to be a target for some work since potentially an application might hit that codepath.
The Weird
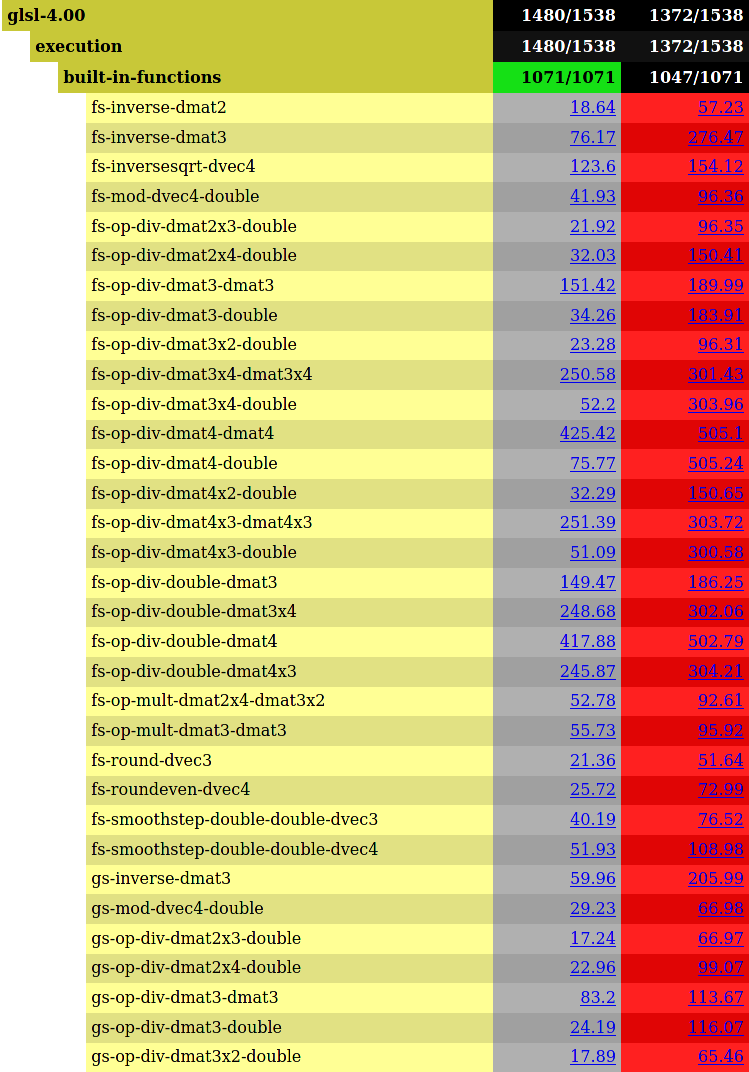
Somehow, zink is noticeably slower in a bunch of other fp64 tests (and this isn’t the full list, only a little over half). It’s strange to me that zink can perform better in certain fp64 cases but then also worse in others, but I’m assuming this is just the result of different shader optimizations happening between the drivers, shifting them onto slightly less slow parts of the softfp64 codepath in certain cases.
Possibly something to look into.
Probably not in too much depth since softfp64 is some pretty crazy stuff.
In Closing
Tests (and especially piglit ones) are not indicative of real world performance.