Through The Loop
A New Level Of Speed
I know everyone’s been eagerly awaiting the return of the pasta maker.
The wait is over.
But today we’re going to move away from those dangerous, addictivive synthetic benchmarks to look at a different kind of speed. That’s right. Today we’re looking at pipeline compile speed. Some of you are scoffing, mouse pointer already inching towards the close button on the tab.
Pipeline compile speed in the current year? Why should anyone care when we have great tools like Fossilize that can precompile everything for a game over the course of several hours to ensure there’s no stuttering?
It turns out there’s at least one type of pipeline compile that still matters going forward. Specifically, I’m talking about fast-linked pipelines using VK_EXT_graphics_pipeline_library.
Let’s get an appetizer going, some exposition under our belts before we get to the spaghetti we’re all craving.
Pipelines: They’re In Your Games
All my readers are graphics experts. It won’t come as any surprise when I say that a pipeline is a program containing shaders which is used by the GPU. And you all know how VK_EXT_graphics_pipeline_library enables compiling partial pipelines into libraries that can then be combined into a full pipeline. None of you need a refresher on this, and we all acknowledge that I’m just padding out the word count of this post for posterity.
Some of you experts, however, have been so deep into getting those green triangles on the screen to pass various unit tests that you might not be fully aware of the fast-linking property of VK_EXT_graphics_pipeline_library.
In general, compiling shaders during gameplay is (usually) bad. This is (usually) what causes stuttering: the compilation of a pipeline takes longer than the available time to draw the frame, and rendering blocks until compilation completes. The fast-linking property of VK_EXT_graphics_pipeline_library changes this paradigm by enabling pipelines, e.g., for shader variants, to be created fast enough to avoid stuttering.
Typically, this is utilized in applications through the following process:
- create pipeline libraries from shaders during game startup or load screen
- wait until pipeline is needed at draw-time
- fast-link final pipeline and use for draw
- background compile an optimized version of the same pipeline for future use
In this way, no draw is blocked by a pipeline creation, and optimized pipelines are still used for the majority of GPU operations.
But Why…
…would I care about this if I have Fossilize and a brand new gaming supercomputer with 256 cores all running at 12GHz?
I know you’re wondering, and the answer is simple: not everyone has these things.
Some people don’t have extremely modern computers, which means Fossilize pre-compile of shaders can take hours. Who wants to sit around waiting that long to play a game they just downloaded?
Some games don’t use Fossilize, which means there’s no pre-compile. In these situations, there are two options:
- compile all pipelines during load screens
- compile on-demand during rendering
The former option here gives us load times that remind us of the original Skyrim release. The latter probably yields stuttering.
Thus, VK_EXT_graphics_pipeline_library (henceforth GPL) with fast-linking.
The Obvious Problem
What does the “fast” in fast-linking really mean?
How fast is “fast”?
These are great questions that nobody knows the answer to. The only limitation here is that “fast” has to be “fast enough” to avoid stuttering.
Given that RADV is in the process of bringing up GPL for general use, and given that Zink is relying on fast-linking to eliminate compile stuttering, I thought I’d take out my perf magnifying glass and see what I found.

Uh-oh
Obviously we wouldn’t be advertising fast-linking on RADV if it wasn’t fast.
Obviously.
It goes without saying that we care about performance. No credible driver developer would advertise a performance-related feature if it wasn’t performant.
RIGHT?
And it’s not like I tried running Tomb Raider on zink and discovered that the so-called “fast”-link pipelines were being created at a non-fast speed. That would be insane to even consider—I mean, it’s literally in the name of the feature, so if using it caused the game to stutter, or if, for example, I was seeing “fast”-link pipelines being created in 10ms+…

Surely I didn’t see that though.

Surely I didn’t see fast-link pipelines taking more than an entire frame’s worth of time to create.
It’s Fine
Long-time readers know that this is fine. I’m unperturbed by seeing numbers like this, and I can just file a ticket and move on with my life like a normal per—

OBVIOUSLY I CAN’T.
Obviously.
And just as obviously I had to get a second opinion on this, which is why I took my testing over to the only game I know which uses GPL with fast-link: 3D Pinball: Space Cadet DOTA 2!
Naturally it would be DOTA2, along with any other Source Engine 2 game, that uses this functionality.
Thus, I fired up my game, and faster than I could scream MID OR MEEPO into my mic, I saw the unthinkable spewing out in my console:
COMPILE 11425115
COMPILE 39491
COMPILE 11716326
COMPILE 35963
COMPILE 11057200
COMPILE 37115
COMPILE 10738436
Yes, those are all “fast”-linked pipeline compile times in nanoseconds.
Yes, half of those are taking more than 10ms.

First Steps
The first step is always admitting that you have a problem, but I don’t have a problem. I’m fine. Not upset at all. Don’t read more into it.
As mentioned above, we have great tools in the Vulkan ecosystem like Fossilize to capture pipelines and replay them outside of applications. This was going to be a great help.
I thought.
I fired up a 32bit build of Fossilize, set it to run on Tomb Raider, and immediately it exploded.
Zink has, historically, been the final boss for everything Vulkan-related, so I was unsurprised by this turn of events. I filed an issue, finger-painted ineffectually, and then gave up because I had called in the expert.
That’s right.
Friend of the blog, artisanal bit-wrangler, and a developer whose only speed is -O3 -ffast-math, Hans-Kristian Arntzen took my hand-waving, unintelligible gibbering, and pointing in the wrong direction and churned out a masterpiece in less time than it took RADV to “fast”-link some of those pipelines.
While I waited, I was working at the picosecond-level with perf to isolate the biggest bottleneck in fast-linking.
Fast-linking: Stop Compiling.
My caveman-like, tool-less hunt yielded immediate results: nir_shader_clone during fast-link was taking an absurd amount of time, and then also the shaders were being compiled at this point.
This was a complex problem to solve, and I had lots of other things to do (so many things), which meant I needed to call in another friend of the blog to take over while I did all the things I had to do.
Some of you know his name, and others just know him as “that RADV guy”, but Samuel Pitoiset is the real deal when it comes to driver development. He can crank out an entire extension implementation in less time than it takes me to write one of these long-winded, benchmark-number-free introductions to a blog post, and when I told him we had a huge problem, he dropped* everything and jumped on board.
* and when I say “dropped” I mean he finished finding and fixing another Halo Infinite hang in the time it took me to explain the problem
With lightning speed, Samuel reworked pipeline creation to not do that thing I didn’t want it to do. Because doing any kind of compiling when the driver is instead supposed to be “fast” is bad. Really bad.
How did that affect my numbers?
By now I was tired of dealing with the 32bit nonsense of Tomb Raider and had put all my eggs in the proverbial DOTA2 basket, so I again fired up a round, went to AFK in jungle, and checked my debug prints.
COMPILE 55699
COMPILE 55998
COMPILE 58016
COMPILE 56825
COMPILE 60288
COMPILE 110663
COMPILE 59679
COMPILE 50614
COMPILE 54316
Do my eyes deceive me or is that a 20,000% speedup from a single patch?!
Problem Solved
And so the problem was solved. I went to Dan Ginsburg, who I’m sure everyone knows as the author of this incredible blog post about GPL, and I showed him the improvements and our new timings, and I asked what he thought about the performance now.
Dan looked at me. Looked at the numbers I showed him. Shook his head a single time.
It shook me.
I don’t know what I was thinking.
In my defense, a 20,000% speedup is usually enough to call it quits on a given project. In this case, however, I had the shadow of a competitor looming overhead.
While RADV was now down to 0.05-0.11ms for a fast-link, NVIDIA can apparently do this consistently in 0.02ms.
That’s pretty fast.
Even Faster
By now, the man, the myth, @themaister, Hans-Kristian Arntzen had finished fixing every Fossilize bug that had ever existed and would ever exist in the future, which meant I could now capture and replay GPL pipelines from DOTA2. Fossilize also has another cool feature: it allows for extraction of single pipelines from a larger .foz file, which is great for evaluating performance.
The catch? It doesn’t have any way to print per-pipeline compile timings during a replay, nor does it have a way to sort pipeline hashes based on compile times.
Either I was going to have to write some C++ to add this functionality to Fossilize, or I was going to have to get creative. With my Chromium PTSD in mind, I found myself writing out this construct:
for x in $(fossilize-list --tag 6 dota2.foz); do
echo "PIPELINE $x"
RADV_PERFTEST=gpl fossilize-replay --pipeline-hash $x dota2.foz 2>&1|grep COMPILE
done
I’d previously added some in-driver printfs to output compile times for the fast-link pipelines, so this gave me a file with the pipeline hash on one line and the compile timing on the next. I could then sort this and figure out some outliers to extract, yielding slow.foz, a fast-link that consistently took longer than 0.1ms.
I took this to Samuel, and we put our perfs together. Immediately, he spotted another bottleneck: SHA1Transform() was taking up a considerable amount of CPU time. This was occurring because the fast-linked pipelines were being added to the shader cache for reuse.
But what’s the point of adding an unoptimized, fast-linked pipeline to a cache when it should take less time to just fast-link and return?
Blammo, another lightning-fast patch from Samuel, and fast-linked pipelines were no longer being considered for cache entries, cutting off even more compile time.
slow.foz was now consistently down to 0.07-0.08ms.
Are We There Yet?
No.
A post-Samuel flamegraph showed a few immediate issues:
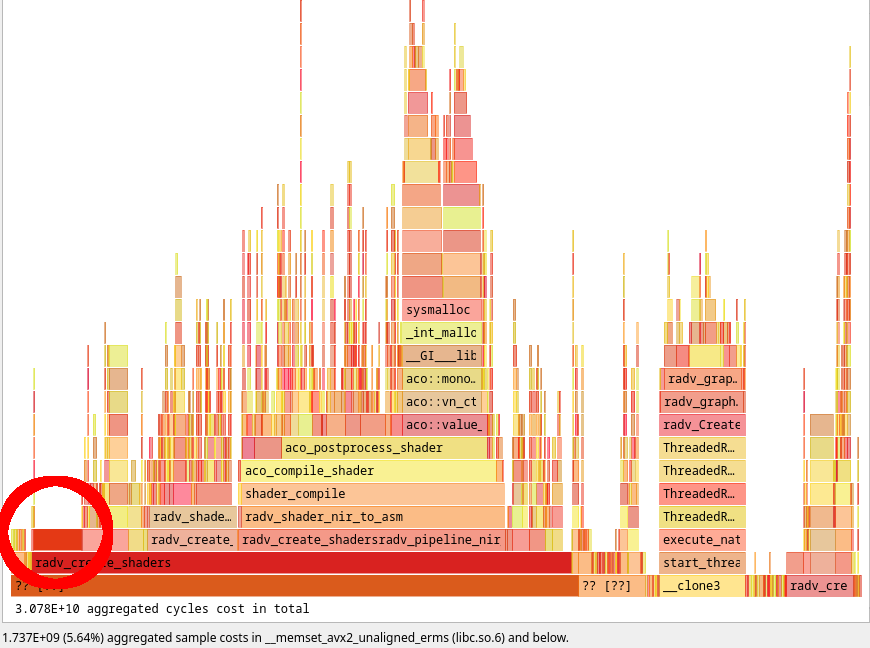
First, and easiest, a huge memset. Get this thing out of here.
Now slow.foz was fast-linking in 0.06-0.07ms. Where was the flamegraph at on this?
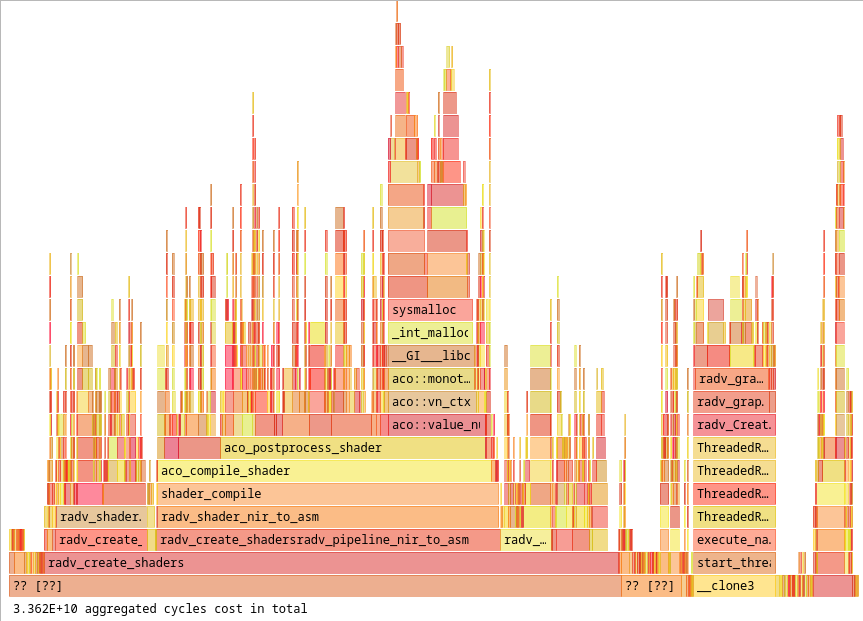
Now the obvious question: What the farfalloni was going on with still creating a shader?!
It turns out this particular pipeline was being created without a fragment shader, and that shader was being generated during the fast-link process. Incredible coverage testing from an incredible game.
Fixing this proved trickier, and it still remains tricky. An unsolved problem.
However.
<zmike> can you get me a hack that I can use for that foz ?
* zmike just needs to get numbers for the blog
<hakzsam> hmm
<hakzsam> I'm trying
Like a true graphics hero, that hack was delivered just in time for me to run it through the blogginator. What kinds of gains would be had from this untested mystery patch?
slow.foz was now down to 0.023 ms (23566 ns).
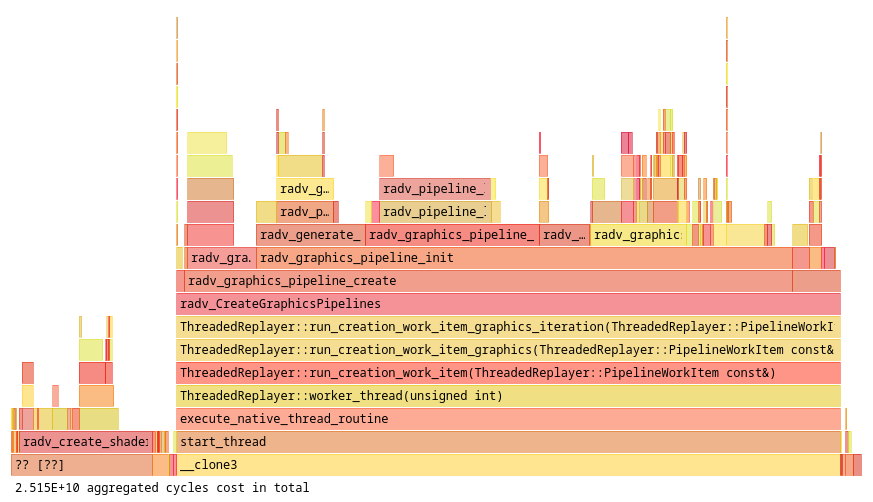
We Did It
Thanks to Hans-Kristian enabling us and Samuel doing a lot of heavy and unsafe lifting while I sucked wind on the sidelines, we hit our target time of 0.02ms, which is a 50,000% improvement from where things started.
What does this mean?
If You’re A User…
This means in the very near future, you can fire up RADV_PERFTEST=gpl and run DOTA2 (or zink) on RADV without any kind of shader pre-caching and still have zero stuttering.
If You’re A Game Developer…
This means you can write apps relying on fast-linking and be assured that your users will not see stuttering on RADV.
If You’re A Driver Developer…
So far, there aren’t many drivers out there that implement GPL with true fast-linking. Aside from (a near-future version of) RADV, I’m reasonably certain the only driver that both advertises fast-linking and actually has fast linking is NVIDIA.
If you’re from one of those companies that has yet to take the plunge and implement GPL, or if you’ve implemented it and decided to advertise the fast-linking feature without actually being fast, here’s some key takeaways from a week in GPL optimization:
- Ensure you aren’t compiling any shaders at link-time
- Ensure you aren’t creating any shaders at link-time
- Avoid adding fast-link pipelines to any sort of shader cache
- Profile your fast-link pipeline creation
You might be thinking that profiling a single operation like this is tricky, and it’s hard to get good results from a single fossilize-replay that also compiles multiple library pipelines.
Never fear, vkoverhead is here to save the day.
You thought I wouldn’t plug it again, but here we are. In the very near future (ideally later today), vkoverhead will have some cases that isolate GPL fast-linking. This should prove useful for anyone looking to go from “fast” to fast.
There’s no big secret about being truly fast, and there’s no architectural limitations on speed. It just takes a little bit of elbow grease and some profiling.
But Also
The goal is to move GPL out of RADV_PERFTEST with Mesa 23.1 to enable it by default. There’s still some functional work to be done, but we’re not done optimizing here either.
One day I’ll be able to say with confidence that RADV has the fastest fast-link in the world, or my name isn’t Spaghetti Good Code.
UPDATE: It turns out RADV won’t have the fastest fast-link, but it can get a lot faster.